5/5
What aspects of trillion-param MoE deployment interest you most? Memory offloading strategies? Dynamic routing budgets? Hierarchical expert organization? Drop your thoughts below 👇 #MoE#LLMs#SparseModels#AIResearch
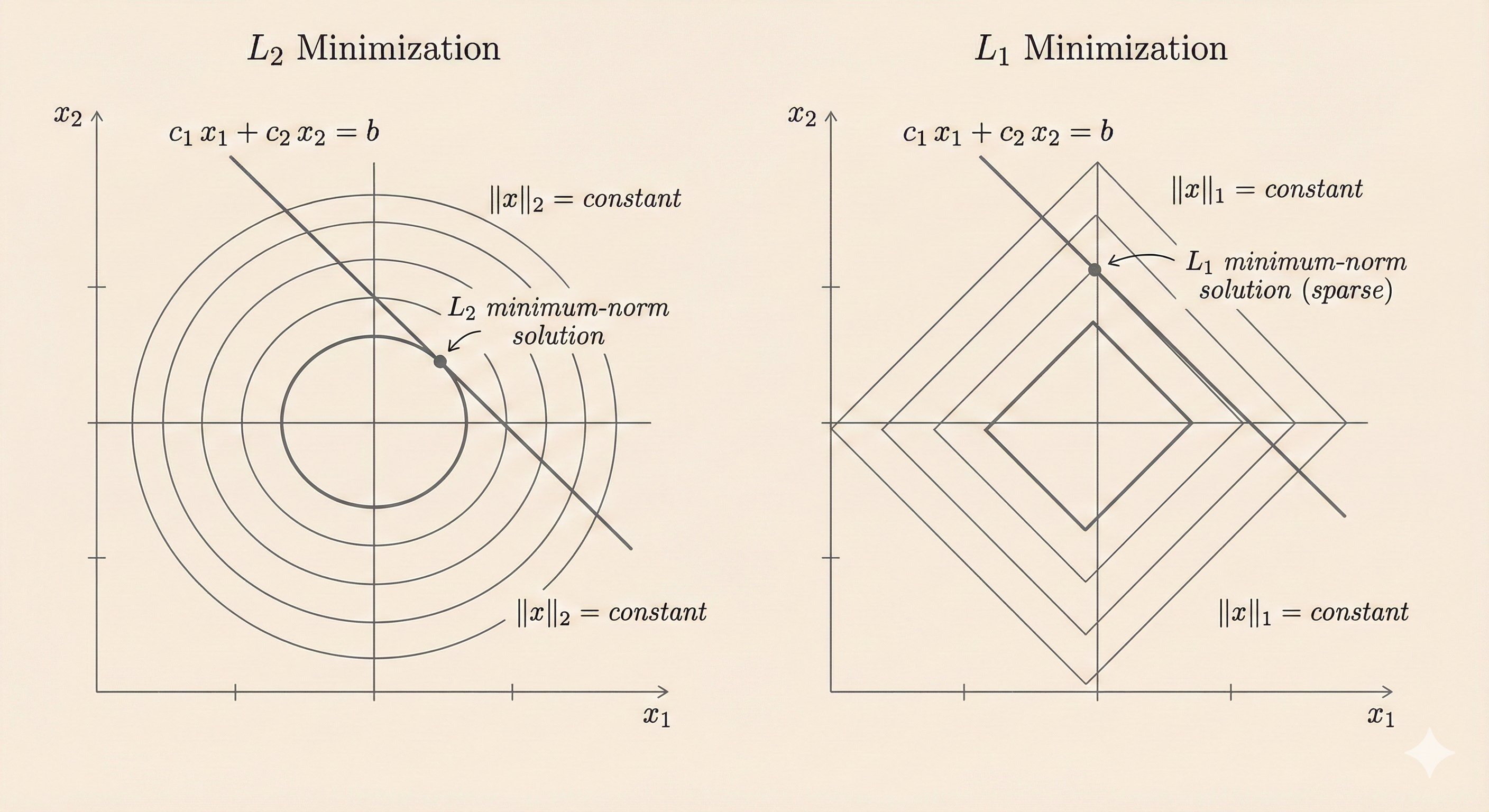
Jonathan Schwarz et al. introduce #Powerpropagation, a new weight-parameterisation for #neuralnetworks that leads to inherently #sparsemodels. Exploiting the behavior of gradient descent, their method gives rise to weight updates exhibiting a "rich get richer" dynamic.
Powerpropagation: A sparsity inducing weight reparameterisation
pdf: arxiv.org/pdf/2110.00296…
abs: arxiv.org/abs/2110.00296
a new weight-parameterisation for neural networks that leads to inherently sparse models
Tomorrow at @ml_collective DLTC reading group, @KaliTessera will be presenting our work on how initialization is only one piece of the puzzle for training sparse networks.
Can taking a wider view of model design choices unlock sparse training?
bit.ly/3xFtHKI