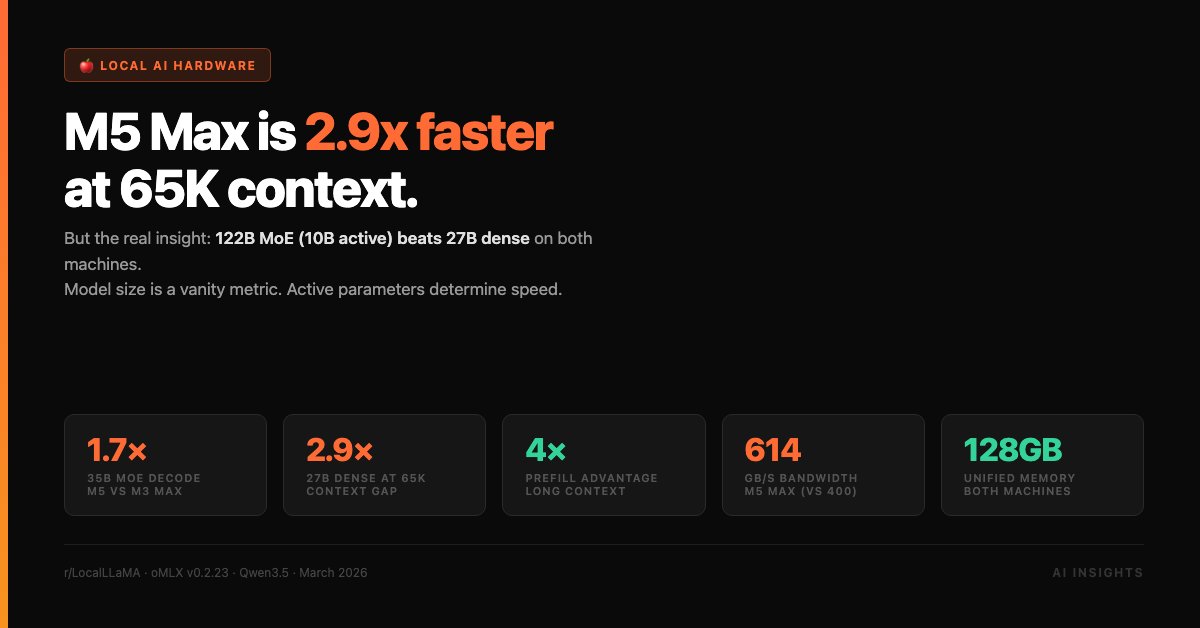
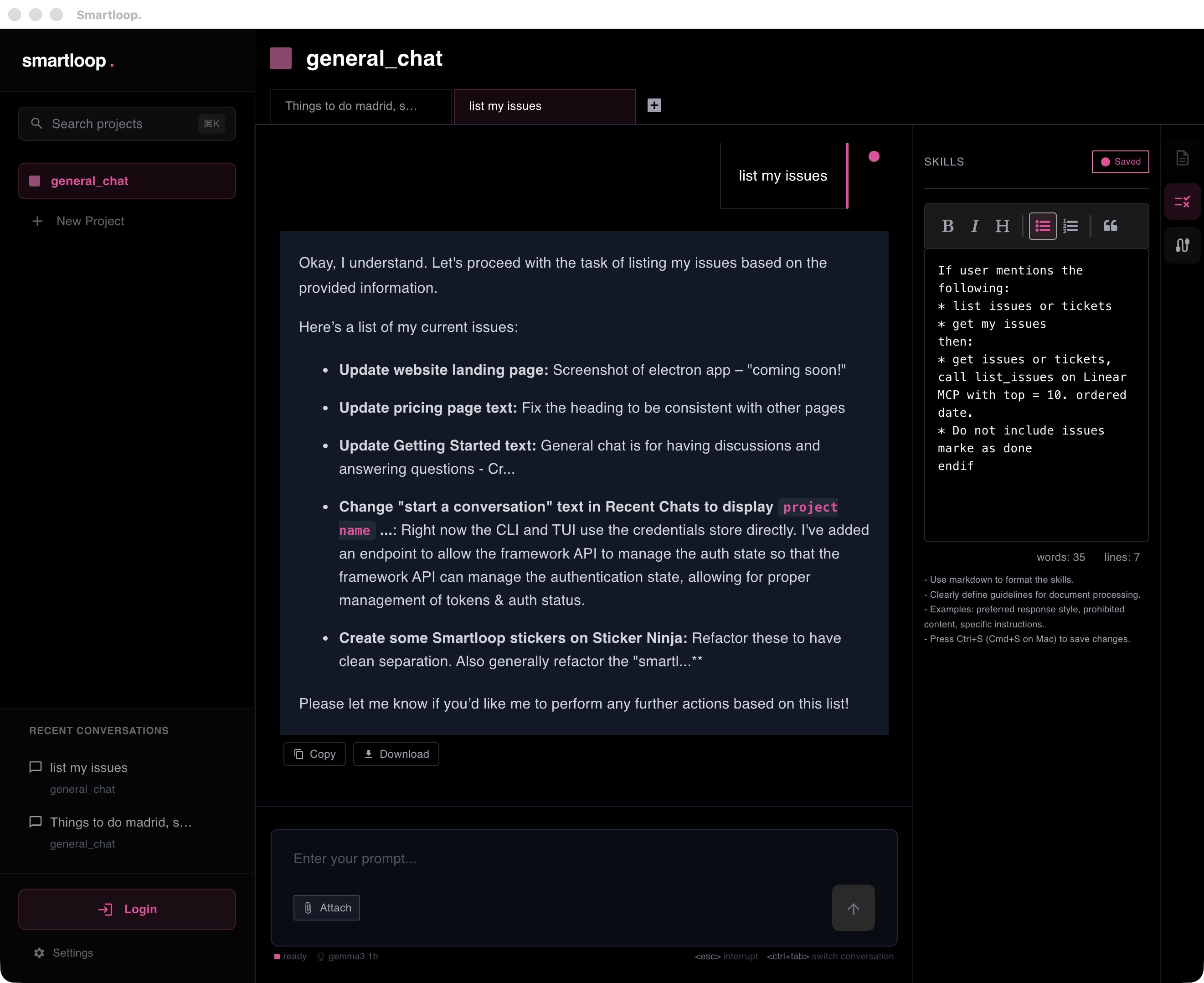
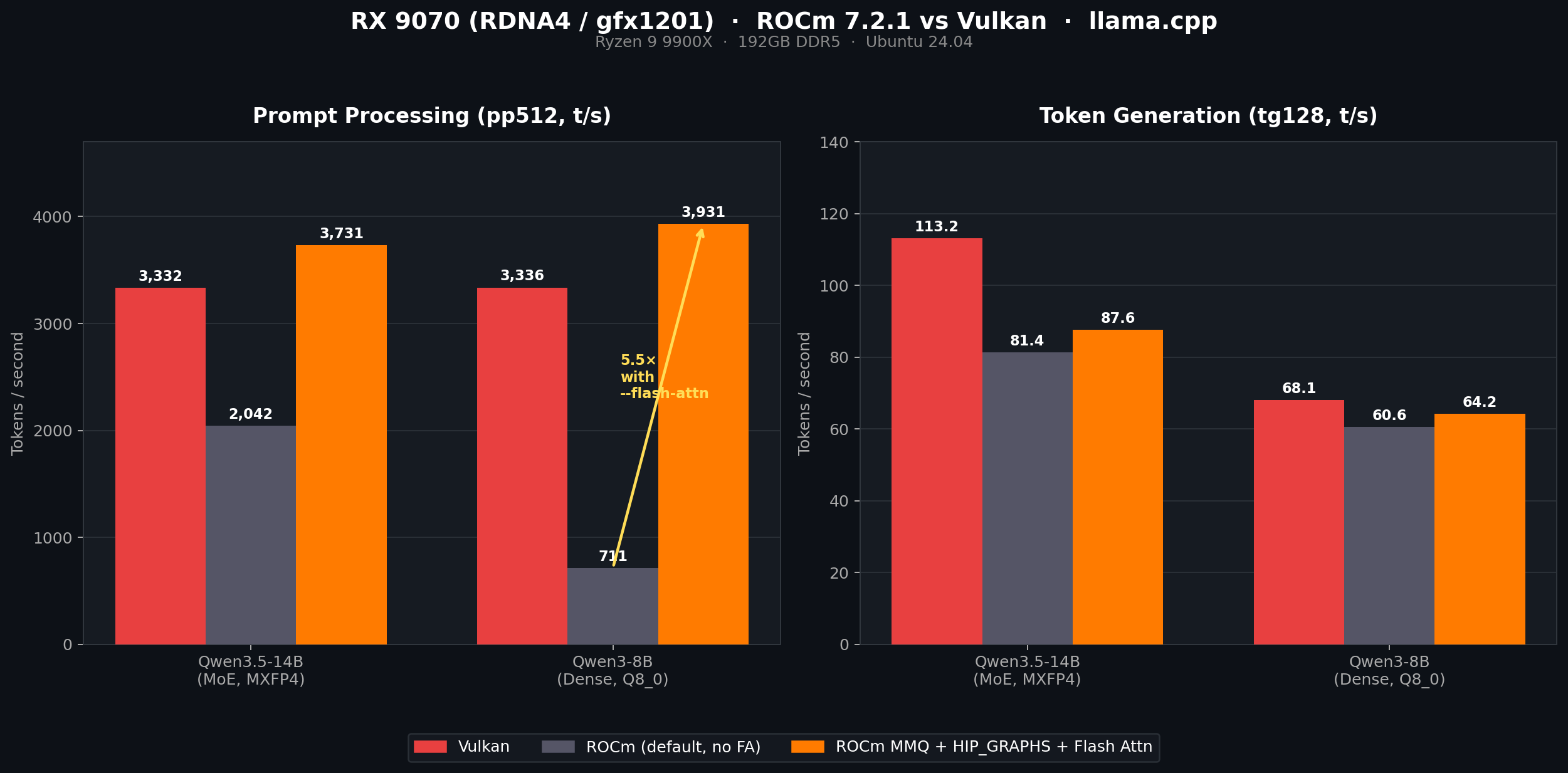
Tool Review Deep Dive: Why 'Local LLMs' are the definitive ROI winner for agencies in 2026. 🛡️🧠💸
Eliminate API costs while increasing security and speed.
Read the full ROI report smartflowslab.com3Tq. #LocalLLM #APIHacking #AgencyROI #TechReview2026 #SmartFlowsL1ec