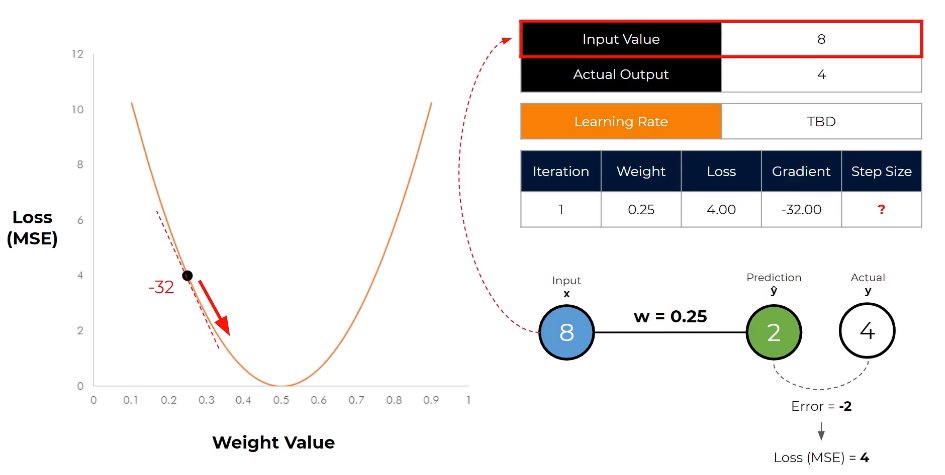
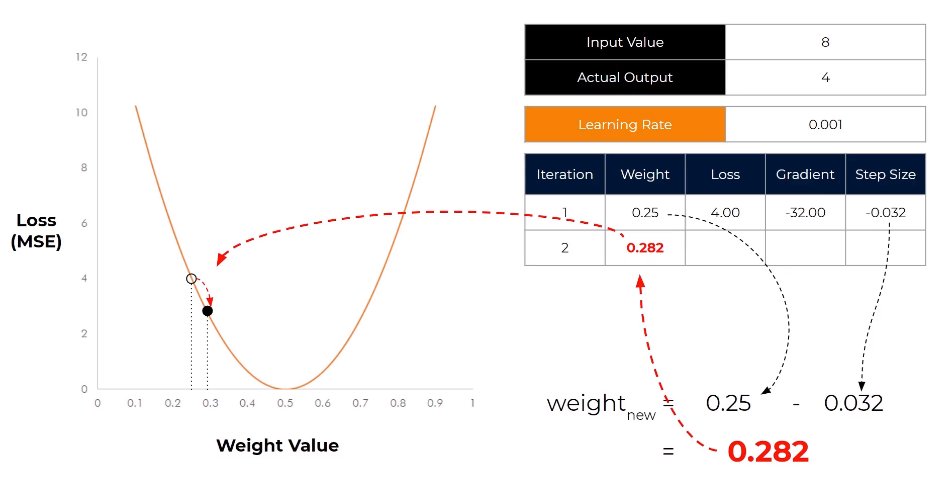
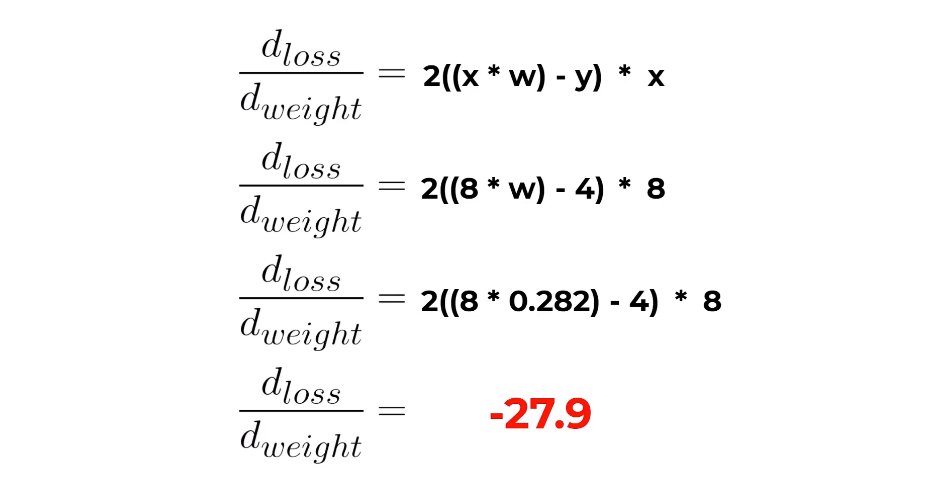Learning rate scheduling adjusts training speed over time—starting fast for quick progress, slowing down for fine-tuning. Like approaching a target: run when far away, walk when close. Adaptive pacing optimizes learning. #AIModelTraining #LearningRate #TrainingOptimization
16