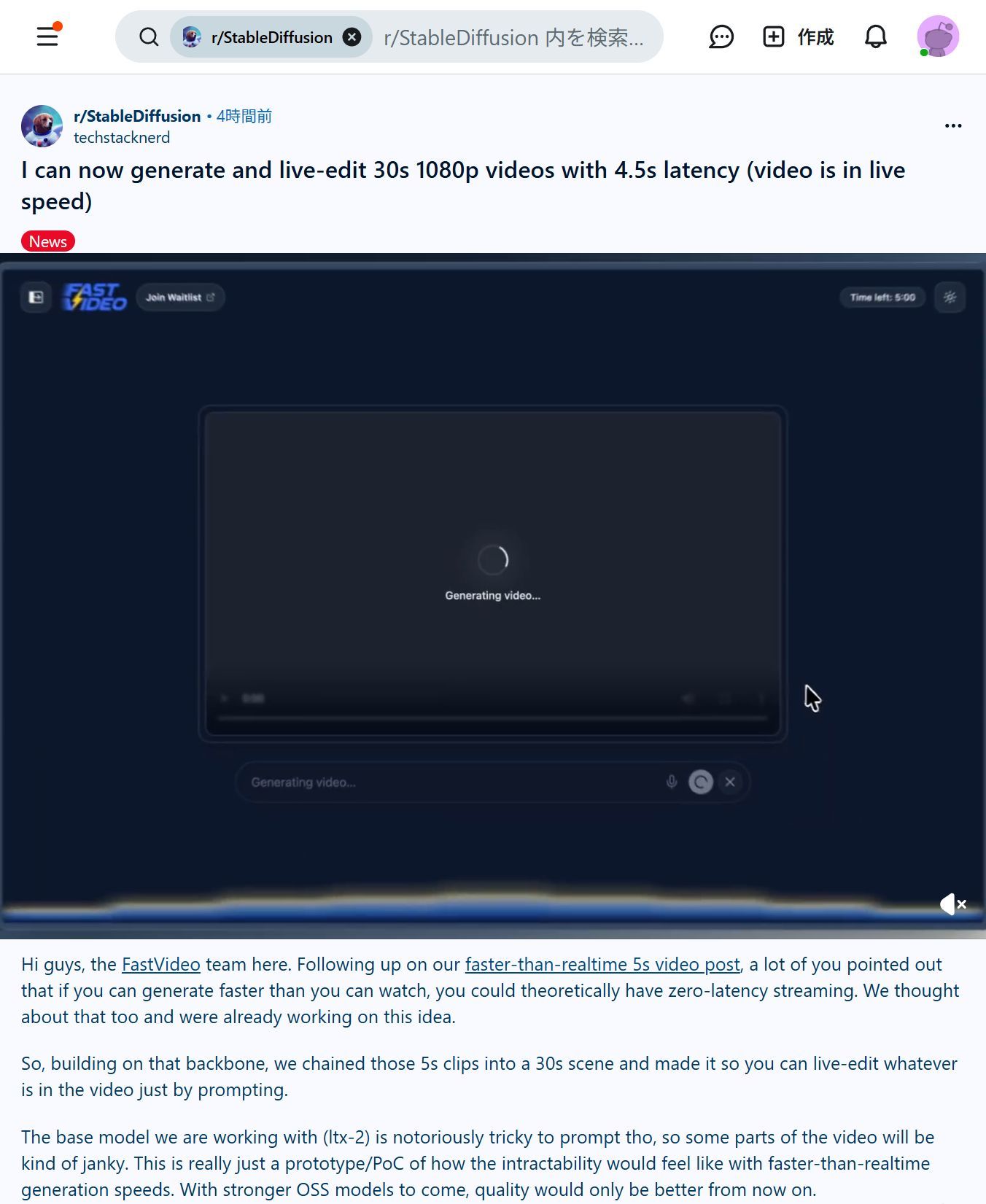
Time is no longer the limit. Powered by #Fastvideo and #K2think,you can make a 30second 1080p video in just just 5 seconds!
Anyone wants to compete? Raise your hands 🙌
A major breakthrough that will tip the landscape of world models! The #FastVideo from Institute of Foundation Models of @mbzuai in collaboration with UC San Diego has demonstrated what becomes possible when generation moves faster than playback, producing 30 seconds of 1080p video in just 5 seconds (unlike other video-gen models like Sora that takes 1-2 minutes to generate a 5s 1080p clip). This result is based on our Faster Video Diffusion with Trainable Sparse Attention, with a reasoning backbone powered by our @K2thinkai LLM which provides real-time reasoning and control — an epitome where generation and intelligence operate together to break limits.
The significance of this breakthrough can not be understated — it shatters a false spell on #GLP (generative latent prediction), a generative architecture of #worldmodel, that it is too computational expensive to be practical whereas encoder-only architectures like #JEPA is more efficient — making GLP a preferred architecture that is both grounded in real world via an encoding-decoding close-loop to avoid hallucination and ensure long horizon consistency, and at the same time computationally efficient and real time auditable and verifiable because of the fast generative capability.
For consumers, it reflects a deeper shift in how we think about media, from something static and pre-defined to something that can be generated, adapted, and experienced in real time.
We can now have an early glimpse of what next-generation World Model will make possible.
Congratulations to @haozhangml and @waterluffy!
33