And before that 6 other math research papers by #Aletheia and other discoveries in physics and computer science, all of which were powered by Gemini #DeepThink! x.com/lmthang/status…
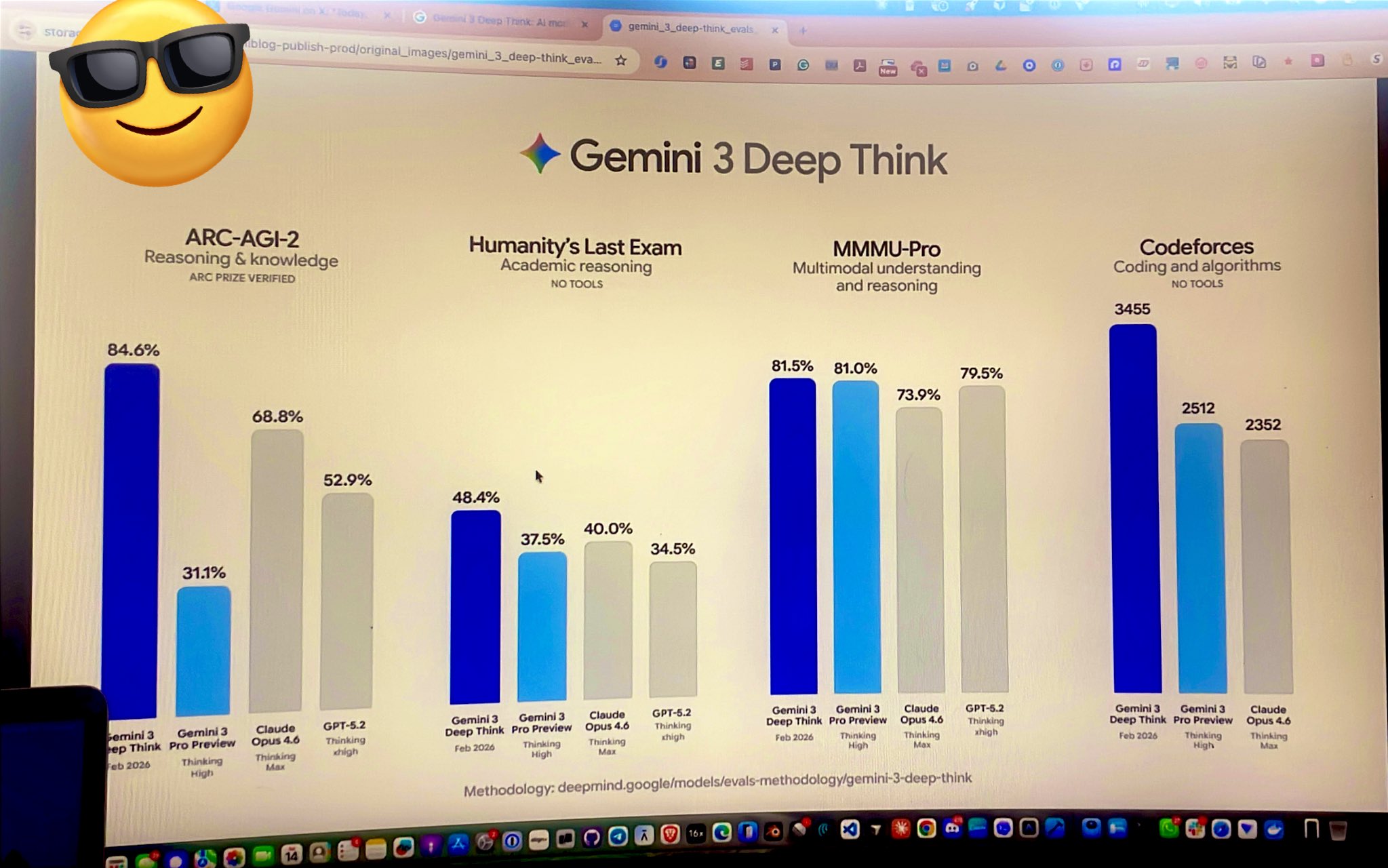
6 months in, after the IMO-gold achievement, I’m very excited to share another important milestone: AI can help accelerate knowledge discovery in mathematics, physics, and computer science! We’re sharing Two new papers from @GoogleDeepMind and @GoogleResearch that explore how #DeepThink together with agentic workflows can empower mathematicians and scientists to tackle professional research problems. Some highlights:
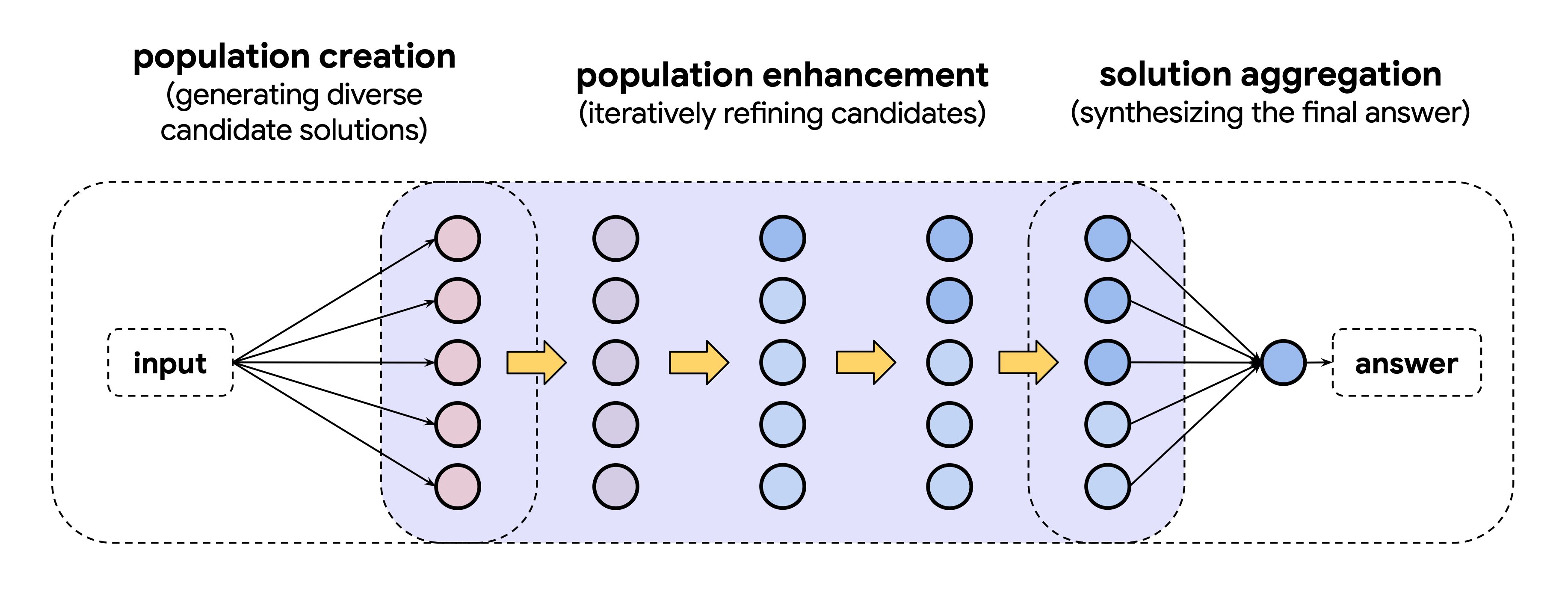
The first paper built a research agent #Aletheia, powered by an advanced version of Gemini Deep Think, that can autonomously produce publishable math research and crack open Erdős problems.
The second paper, built on similar agentic reasoning ideas, helped resolve bottlenecks in 18 research problems, across algorithms, ML and combinatorial optimization, information theory and economics.
See the thread for details about the two papers and the joint blog post.
1
5
1.1K